

声音被耳廓收集,然后耳道和中耳听小骨将对于言语理解重要的频率成分放大,最后经由内耳中的毛细胞传入神经系统。这是声信息传入大脑的典型方式,见图1A。内耳(或耳蜗)可以被看作一个频率分析仪,在耳蜗底部附近的内毛细胞响应和传递高频声信息(约20 kHz),在耳蜗顶部附近的内毛细胞响应和传递低频声信息(约20Hz)。毛细胞是这个声传导过程中不可或缺的一个环节,因为它们开启的电化学反应使得螺旋神经节和听神经将声信息以锋电位的形式进行传递,最终大脑将其解释为声音。然而毛细胞可能受损或死亡,原因包括,为避免某种致死遗传疾病而使用具有耳毒性的药物、长期暴露在高强度声环境中、衰老等。哺乳动物的毛细胞在死亡以后是不能再生的,这意味着在缺失可用的毛细胞的情况下,如果想向大脑传递声信息,我们需要一个跨过毛细胞的方法,人工耳蜗(cochlear implant, CI)就是这个原理。
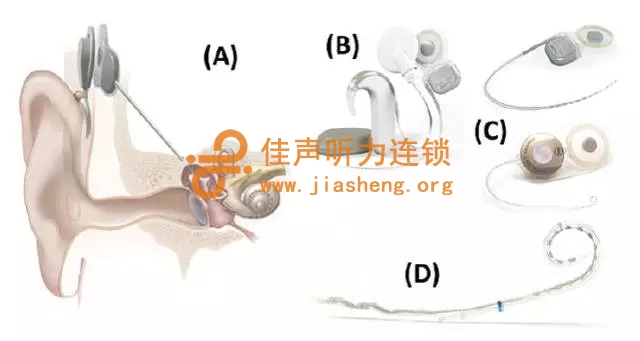
图1. A: 耳廓、耳道、中耳、内耳(即耳蜗)的结构图。人工耳蜗旁路了这些结构,该设备包含,一个带有传声器的耳背式言语处理器、一个调频发射器(位于皮外)、一个接收器(位于皮下)、位于耳蜗内的电极阵列。CI模拟了耳蜗的频率分析功能,将不同的频率信息发送到不同的位置。B: 采用SONNET和RONDO言语处理器的Med-El SYNCHRONY人工耳蜗系统。C: 线圈状调频接收器和电极阵列的特写,其中电极阵列沿着耳蜗(两圈半的蜗牛壳的形状)的螺旋状旋进去。给出了两款:上面一个是Med-El SONNET,下面一个是AB HiRes 90K。D: AB HiRes 90K植入体的电极触点。图片由AB和Med-El公司提供。
现代CI是一种生物医疗设备,它包含一个带有传声器的耳背式言语处理器(也有体配式)和一个位于耳蜗内的电极阵列(包含植入体、图1)。它通过电极直接兴奋与听神经相连的螺旋神经节,来传递对于言语理解最重要的频率成分(通常是200-8000Hz),因此旁路了凋亡的毛细胞。另一方面,与毛细胞的正常化学转换不同,CI刺激以电的形式开启了神经中的电化学转换过程。每个电极触点被分配了一个频率范围,并且频率和位置的分配关系与正常耳蜗的频率分布方式相仿,高频在底部附近,低频位于顶部附近。因此CI模仿了耳蜗的频率位置关系,进而能够提供一个频率分析仪的功能。
今天的CI是现代生物医学工程的奇迹,是最成功的感觉假体。效果最好CI植入者们能够在安静环境下获得近乎完美的言语理解能力,且能够打电话。他们无需借助视觉信息即可理解这种复杂的语音信号。现代多电极CI的先驱们(墨尔本大学的已退休的Graeme M. Clark; 位于因斯布鲁克的MED-EL公司的Ingeborg Hochmair; 杜克大学的Blake S. Wilson)“因开发了这种能给极重度耳聋者重建听力的现代CI设备”而获得了Lakser奖(Pierce, 2013)。
美国国立卫生研究院(NIH)的耳聋和其他沟通障碍研究所(NIDCD)估计全球有超过32.4万名CI植入者(NIDCD, 2012)。这些植入者的年龄覆盖所有年龄段,儿童植入者的年龄越来越小(有的在6个或9个月大时,可以这样做是因为在婴儿出生时耳蜗的大小基本固定,随着年龄的增长很小),老年植入者的年龄越来越高(有的甚至达到了90多岁)。
对于婴儿和老人来说,他们的生理结构更脆弱,那为什么还要冒着风险开展外科手术呢?这是因为,人们由于生活质量遇到问题而选择进行耳蜗植入。人类是社会性的动物,当失去了与他人交流的能力,可能变得孤独沮丧。在很多实际生活场合中人们依赖听觉来进行通信和社交。另外,即便在其他通信方式存在的条件下,听力损失会中断与那些已经建立的社交圈、朋友、家人的沟通方式。
可以说,CI信号处理的最近的主要进展发生在20多年前(Wilson et al. 1991),当时引入了多通道高速率策略(每单个电极上的刺激率接近每秒钟1000个脉冲,而不是早期CI中的每秒钟100个脉冲)。今天的现代植入体有12到22个蜗内电极,这些通道传递的信息是时域包络信息(信号中的慢变时域信息,而不是快速振荡的载波或精细结构;见图2)。
所有的CI都采用了“声码器架构”的信号处理方式(Loizou, 2006)。这种方式源于Dudley (1959)设计的一种用于高效信息编码的方法。将频谱划分到各个信息通道中,保留了比常规声听觉更粗糙的分辨率(见图2分析阶段),但是这种分辨率对于言语理解已足够了。CI使用者能利用的离散通道个数是10个左右,然而常规听觉系统能被看作是由一组连续的听觉滤波器构成的,其中提供了更精细的频率分辨率。正常听觉与CI之间的比较,就好像现代图形计算器和老式机械计算器之间的比较。如果你只知道机械计算器,那么能为你进行对数计算的现代图形计算器看上去是多么伟大而惊艳。然而,从小就在使用现代图形计算器的人,则难以容忍机械计算器,不在迫不得已的情况下也不会用它配合查表法来完成对数计算。
CI从每个通道提取时域包络。在工程实验时,提取方法会有区别,但是基本思想是一样的。所需要的是慢变幅度调制信息,而不是时域精细结构中的所有快速变化。所以对每个通道进行包络提取操作(见图2包络提取阶段)。
最后加载波。每个通道中提取的包络被用于调制高速电载波信号的幅度(见图2加载波阶段)。然后这些调制过的电脉冲串旁路掉耳蜗中死掉的毛细胞直接兴奋连接听神经螺旋神经节,并进一步被解释为声音和言语。因为这个原因,人们常说CI传递了时域而不是频率与信息。然而,这种说法不是严格正确的,因为仅提供一个通道的时域包络信息不能提供很好的言语可懂度(这正是CI放弃了早年的单电极植入的原因)。实际上,CI在相对有限数量的频率通道上表达了时域包络信息。现在使用的频率通道数目足以传递元音信息(Laback et al., 2004),但是更精细的频率信息分辨任务对于CI使用者看上去难以完成(Goupell et al., 2008)。
很明显,与正常听力利用的信息比较,在这个过程中,所传递的总信息已经被大大减少了。幸运的是,CI的首要目的是传递语音信息。语音信号是一种具有大量的冗余信息的信号。正是这种冗余性,让移动电话在传送一个非常有限的频谱的同时传递了全部的信息,这样就可以避免移动电话网的阻塞。同样地,CI能到达目前的效果的唯一原因是我们有这样难以被破坏的信号。
在视觉方面,有一个例子(Harmon and Julesz, 1973)可以对CI的有效性进行比喻。图3中第一行展示了一副图像的分辨率从非常低逐渐升高。在最左图中,你可以察觉到这张图有内容,但是你不能辨认其中人物是谁。最右图则是高清图片。但是就像CI一样,人们并不需要非常高的分辨率就已经可以猜出图中的内容。并且,经过一定的练习,多数人都能辨认出第二行中低分辨率总统照片的身份。

图3. A: 从左至右是分辨率从低到高的乔治华盛顿的照片。B: 低分辨率版本(20个像素)的乔治·布什、比尔·克林顿、巴拉克·奥巴马、和罗纳德·里根的照片。这些照片均取自可开放获取的官方发布的总统肖像。
正如前面提到的,CI传递到听觉系统的信号中丢弃了大量的声信息。CI领域中有很多方面有待改进,其中两个最大的问题是(1)音乐、音高、和噪声问题,(2)空间听觉和噪声问题。
没错,“噪声”被两次提及。生活是凌乱吵闹的,然而CI不能在噪声中实现言语理解(例如,Loizou et al., 2009)。选择植入CI的主要缘由是为了获取、恢复或重建对语音的理解,很多时候我们处于喧闹的环境中,所以CI在噪声中的性能有待提升。
鲜有耳闻说谁会因为不能再听音乐而放弃使用CI。
的确如此,对于多数CI使用者来说,音乐体验效果有限(对更依赖旋律表达的古典音乐和交响乐,可能尤甚;对于依赖节奏和节拍的饶舌和舞曲,可能稍好些)。因为CI只传达了时域包络信息,并将原始包络替换为脉冲串(见图2),所以大部分“时域音高”(即由波形周期性传递的音高)就不存在了。部分“位置音高”(即兴奋的神经元的位置不同而具有不同的特征频率,进而产生不同的音高)保留了下来。当然,并非全部时域音高都没有了,因为在时域包络中仍传达了一些时域音高(足以提供分辨话者性别的能力,当然与声听觉相比会弱一些)(Fu et al., 2004)。我们希望CI使用者能够出去参加社交活动,比如在一个嘈杂的餐厅或鸡尾酒会,精细结构或周期性信息的缺失严重限制了他们的体验。精细结构或周期性信息的缺失,或称这些听觉分组信息(这里的分组是指大脑在听觉场景中剥离出一个个单个听觉客体的能力)的缺失,是第一大问题。这种听觉分组信息的缺失,导致包络混杂在一起,使声音听上去就混沌不堪。
在缺乏时域精细结构和周期性的分组信息的情况下,与空间听觉相关的分组信息(即那些在双耳间的提供辨别声音来向的信息)则显得特别重要。这是本领域中的第二大问题。人类有两只耳朵,在它们的帮助下我们可以计算声音到达两耳的时间和强度差来实现声音定位。
另外,两只耳朵让我们能在噪声环境下更好的理解语音。越来越多人选择植入双侧CI,以期望获得空间听觉能力。在正常听力中,当其他分组信息(例如音高)失效时,空间信息可以提供不错的听觉场景分析能力(例如,Brungart, 2001)。这种信息让听力者在一个喧闹拥挤的聚会中捕捉到他所注意的人的讲话,即便此时周围还有一些同性别的有相同音高的人在讲话。
因此,在我们重建时域精细结构和周期性的分组信息(如果我们能修复周期性和音高,那么我们可能修复方方面面的听觉功能)前,CI使用者需要获得一些其他的信息来进行听觉场景分析。近水楼台的可能就是空间听觉信息。现在,双侧CI使用者比单侧CI使用者在空间声源定位和噪声中的言语理解方面表现更好,但是距离提供完美的空间信息还很远。
怎样才可能改善CI在这些方面的感知呢?这受到了一些方面的限制,包括生物学的、手术方面的、和设备相关的等(Litovsky et al., 2012)。但是本领域普遍采用了“工程学的方式”来解决问题。失聪的耳朵不能按照原本应该的样子进行工作,为了修复它,我们需要知道应该向听觉系统传递什么信息,然后想办法传递它。
可以说,工程学的方式会假设更多的信息就会得到更好的效果,因此实际的限制因素在于需要更好的技术。在这方面,之所以最近的重大突破发生在20年前是有原因的。(在过去20年中取得了很多进展,例如电池寿命增长、设备更小更耐用、传声器波束形成基础提供了更好的抗环境噪声的性能;然而,在上世纪九十年代后在言语理解方面没有出现新的革命性变化)。与此相反,人们可以换个角度,由于CI能够传递的信息量是有限的,那么应该尝试只传递最重要的信息。这个思路相对不是特别流行,但是存在于一些言语处理策略中。难道还不应该谨慎地重新思考,我们应该在表达声信息时如何最大化听觉系统接收到的“有用”信号吗?例如,尽管有些CI使用者有22个电极触点,那么人们可能认为这会提供22个信息通道。不幸的是,事实并非如此。受到了电流经过耳蜗后如何回收方面的技术限制(地电极的位置决定着电流回收通路),电场扩展很广,大约4到5mm(Helson et al., 2008)。对于35mm的耳蜗,这意味着每个电极兴奋了耳蜗的1/8。因此,虽然有些CI用户有22个蜗内电极,但是他们只能利用7或8个独立信息通道,这也就不足以外了。希望不久的将来能开发出更好地技术来提供更多的独立信息通道。
如果CI使用者只能获取大约8个通道的信息,那么我们应该如何表达信息呢?也许可以简单的避免传递全部信号给听觉系统。一种方式是,每次只激活信号能量的最大8个通道,因为这些通道中有最重要的信息(例如,元音共振峰)。仅在部分电极放电的这种峰值选择言语处理策略被广泛使用。这种做法和mp3编码中除去可能被掩蔽的信息的思想差不太多。另外,在“更少就是更多”的思想指引下,很多研究者发现关闭那些由于各种原因被认为是“坏”的电极(例如,差的调制检测能力)可能提升言语识别效果(Garadat et al., 2012)。
另一种方式,是在信号被传递到听觉系统前对它做更多的优化。换言之,为何不对信号进行预处理并尝试得到一个相对更干净的语音表达形式呢?在进入听觉系统前,将噪音分离出来,这个技术在助听器中非常有效,对CI也是一个简洁的技术手段。当然,若此事很简单,我们就可以完成对CI的研究了。在没有先验信息的条件下从噪声中把目标音分离出来是一个高难度的任务。因此,要将CI性能推进到更高的水平,可能不仅需要对听觉系统如何编码电刺激进行基础研究和认识,还需要想办法最大化重要信息的传递(相比于给听觉系统强加尽量多的信息,我们需要在信息筛选上做出明智的选择)和在信息进入听觉系统前尽量移除像背景噪声这种不想要的信息。
美国声学学会会刊(JASA)几乎每一期都有关于CI或CI仿真处理(即声码器;见下文)的文章。上世纪九十年代的两件事催生了这个趋势。
第一个是,在多数植入者中CI开始能够提供高水平的言语理解能力。这就推动了CI的普及,并且其背后的工作原理和大脑如何处理电刺激信号也受到了研究重视。
第二个是,从对基础听觉现象的理解慢慢转向研究在使用助听器或CI的听障者中这些现象的发生规律。虽然这仍然是基础科学范畴,但是听觉方面的转化和如何帮助人们听得更好似乎成为了一个新的研究方向。
然而,虽然我们对听觉有了很多认识,但是要想把我们的认识用于帮助人类才是终极目标,CI已经打开了一个承载未知听觉世界的潘多拉盒子。包络和精细结构的谜团闯入和这个领域。当然,主要编码了包络信息的CI设备,造成所有人都在关注包络和精细结构的主流趋势。我每天在琢磨的一些问题,似乎在传统声听觉系统中不曾被提出,但是当同时考虑传统听觉和CI时这些问题显得异常重要。
下面说说我对人们如何研究CI和电刺激听觉的看法。列出了一些这个领域的亮点。
4.1 好的方面
对于康复效果好的CI使用者(尤其是那些重度听力损失或耳聋时间短的人),言语处理策略提供了很好的听觉功能,特别是在安静环境中(见图4)。虽然大部分时域精细结构被移除了,但是仍有少量的时域音高信息保留在了时域包络中,这可以帮助CI使用者分辨不同的话者性别(Fu et al., 2004)。如前所述,很多人在双侧植入CI,这可以提升他们的空间声定位能力和噪声环境中的言语识别能力。对于后面这个言语能力的提升大多是由于“好耳”效应这种单耳机制。好耳效应简单来说就是有一侧耳可能有一个更好的信噪比(Loizou et al., 2009)。
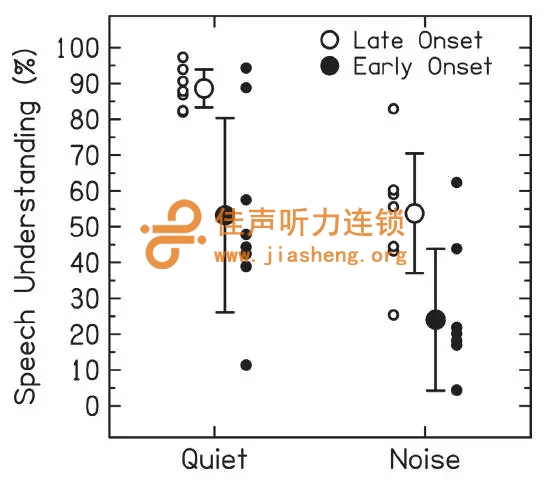
图4. 8位迟发性耳聋(通常是听力损失和耳聋的时间短)和8位早发性耳聋(通常是听力损失和耳聋的时间长)的成年CI听者的言语理解能力。所有被试都是在成年以后进行的CI植入,他们的平均年龄是57岁。在安静环境下或在10dB信噪比的多人交谈噪声条件下采用Az-Bio句子材料进行的言语理解测量。大圆圈是平均言语理解分数±1个标准差。小圆圈是每个人的言语理解分数。图中数据来自马里兰大学Goupell实验室。
CI最初是为了治疗成年语后聋。然而,儿童植入者常常获得非常好的言语、语音发音和言语理解能力(Svirsky et al., 2000)。在年龄谱的另一端,考虑到可能的并发症或言语理解所需的大脑可塑性的缺失,曾有人担心年老者不是最佳的CI适用人群。现在我们已经知道植入年龄没有上限;看上去CI是安全有效的,能够给所有年龄段的植入者带来生活质量的提升。
4.2 差的方面
虽然我们常常赞颂人工耳蜗在以上这些好的效果方面的成功,但是在实际性能上的个体间差异很大(见图4)。纵使很多CI使用者能够在安静环境下获得近乎完美的言语理解能力,但是很多使用者则逊色一些。其中的原因涉及到的方面很广也很多变,但是致聋原因、耳聋时间和植入年龄等因素会对CI言语理解产生影响。可能是由于像我这种研究者在选择被试时的倾向,有时我们容易忘记性能相对更差的CI使用者。成年CI的文献中大多招募的是康复效果好的耳聋时间短的中年CI使用者。但是还有些植入者是语前聋,已经多年没有接受听觉刺激,往往这些人的效果较差。总之,这个领域可以对效果差的这些人给予更多关注。
回到那两个大问题,音高和空间听觉,有几位研究者已经提出了通过降低某些电极上的载波速率来重新引入时域精细结构的一些新的刺激策略。总体而言,尚不清楚这些策略是否能够给音高和空间听觉带来帮助。尽管如此,这个领域似乎正在走向一个正确的方向。最近,Churchill et al., (2014)找到了一种混合速率刺激策略能够表达时域精细结构和包络信息(其中低速率用于表达包络信息和若干蜗尖电极间的相干时域精细结构,高速率只用于表达蜗底电极的包络信息),该方法在改善了声源定位的同时没有对安静环境下的言语理解产生负面影响。
4.3 不确定的方面
我们对听觉系统和电刺激还有很多不知道的事情。例如,传统听觉和CI听觉都不能区分每秒200-300个脉冲以上的声或电脉冲序列(van Hoesel, 2007; Kong et al., 2009),这意味着他们不能区分每秒400和600脉冲。然而,有少量听者可以检测每秒1000个脉冲附近的时域信息变化(Kong and Carlyon, 2010; Noel and Eddington,2013)。这些异常表现挑战了我们对听神经的时间精度和电刺激神经编码的认识。
在前面介绍了CI的频率分辨率有多么低。解决这个问题的一个好的工程学方法是用更多的电极和更小的电场扩展来提高频率分辨率。通过改变地电极的位置来实现其他的极性配置(即从单极变为双极或三极模式),进而可以获得更小的电场扩展。然而,这样做虽然让我们增加了频率分辨率,并且因此我们能够给CI使用者提供更接近传统声听觉的刺激信号,但是这些新的配置至多是带来的结果有好有坏(不确定, mixed results),并且经常给CI使用者带来更差的言语理解程度(Pfingst et al., 2001)。换言之,精细的频率分辨率是经典听觉的标识;然而,在CI中更好的频率分辨率往往没带来什么变化甚至带来了更差的言语理解。这可能是因为我们对听觉运作的理解还不够。或者可能是由于一定需要刺激到耳蜗中的某个部位?但是更高的频率分辨率增加了信息不被良好表达的可能性,因为耳蜗中部分区域(例如神经死区;Shannon et al., 2001)缺少神经节和神经元来传递信息。因此,工程学的这种解决问题方式可能不适用。大范围的电流扩展和带宽保证至少有一些神经元接收到了信息,尽管这并不是我们已知的经典听觉对语音的编码方式。
从Shannon et al. (1995)至今,声码器仿真催生了一个听觉研究的文献量爆发过程。声码器仿真的魅力在于,它实质上的工作方式与图2所示的基于声码器架构的言语处理方式相仿。处理过程中的唯一区别是,在CI中是用调制电脉冲串来对包络编码,而在声码器中用的是正弦波或窄带噪声。所以很多声码器研究的目的是模拟CI处理的某些方面,并且这种技术的主要优点是大多数正常听力者不会表现出实际CI使用者的那么大的变异性。康复效果好的CI植入者与聆听声码器仿真声的正常听力者趋向于获得相近的性能。
CI仿真不限于语音信号。有人曾用带限脉冲串来模拟电脉冲串 (Kan et al., 2013)。然而,应该注意的是声信号永运不能替代电刺激,因为声刺激和电刺激所遵循的物理定律截然不同。尽管如此,完美模仿CI的效果不是声码器的关键目的。一个好的声码器实验是针对CI处理或电刺激的某个方面开展的,目的是更好的理解CI数据。这种仿真永远不是完美的,但是有很多优点,并且对正常听力者获得测试结果的误差线将会更加可控。
Oxehma and Kreft (2014)这篇论文是个很好的例子。文中通过对电极周围的电场扩展进行建模,来解释不同掩蔽类型对语音的掩蔽规律。他们用仿真方法来研究CI的某个方面,将两类人群的数据模式等同起来。可是这样说,关于声码器是否能够有效地被用作CI仿真器的讨论,实际上就是对“建模”的基本意义的讨论。模型是对现实生活的简化,是复杂事务的精简版。很多时候,最佳的模型是简单的。虽然声码器没有考虑很多具体的实际的复杂因素,但它的确是个有用的工具。
总之,CI是一种非常有效的听觉假体,它仿照了内耳的声音编码方式,但是其传递信息的能力受到了严重的限制。CI研究者面临了一些需要翻越的障碍,有成功的经验也有实际的挑战。CI已经激发了一些令人兴奋的新的研究问题,并且已经揭示了一些关于听觉系统的新的谜题。这个领域继续推动着听觉研究的前沿,让我们更好的理解听觉工作原理,并且让我们帮助那些失去或从未有过听力的朋友重建或得到听力。
售前咨询:
售后服务:
技术支持:
服务时间:
8:00-20:00







 辽公网安备:21010602000079号
辽公网安备:21010602000079号